Ziqiang Zheng1 Yuk-Kwan Wong1 Binh-Son Hua2 Jianbo Shi3 Sai-Kit Yeung1
1The Hong Kong University of Science and Technology 2Trinity College Dublin 3University of Pennsylvania
International Conference on Computer Vision, ICCV 2025
DINO,
DINOv2, DINOv3, iBoT,
SAM, SAM2, and
CoralSCOP.
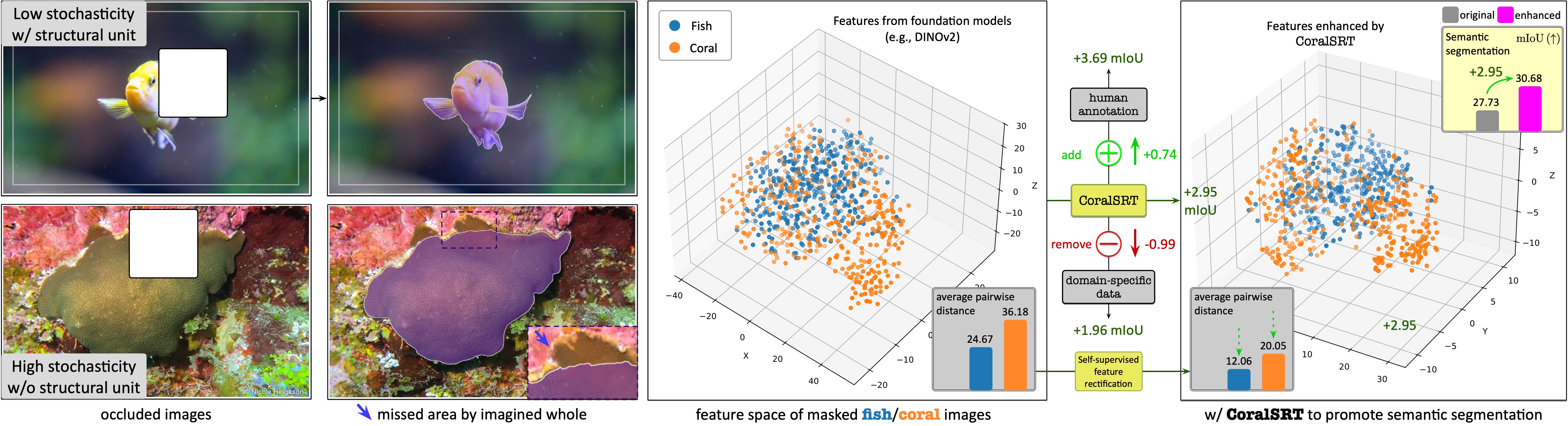
The coral reef semantic segmentation could be categorized as stuff segmentation. COCO-Stuff (Caesar et al., 2018) conducted the first attempt to do stuff segmentation and summarized five key properties between “instances/things” and “stuffs”: shape, size, parts, instances, and texture. Inspired by this work, we have also summarized the challenges of conducting coral segmentation:
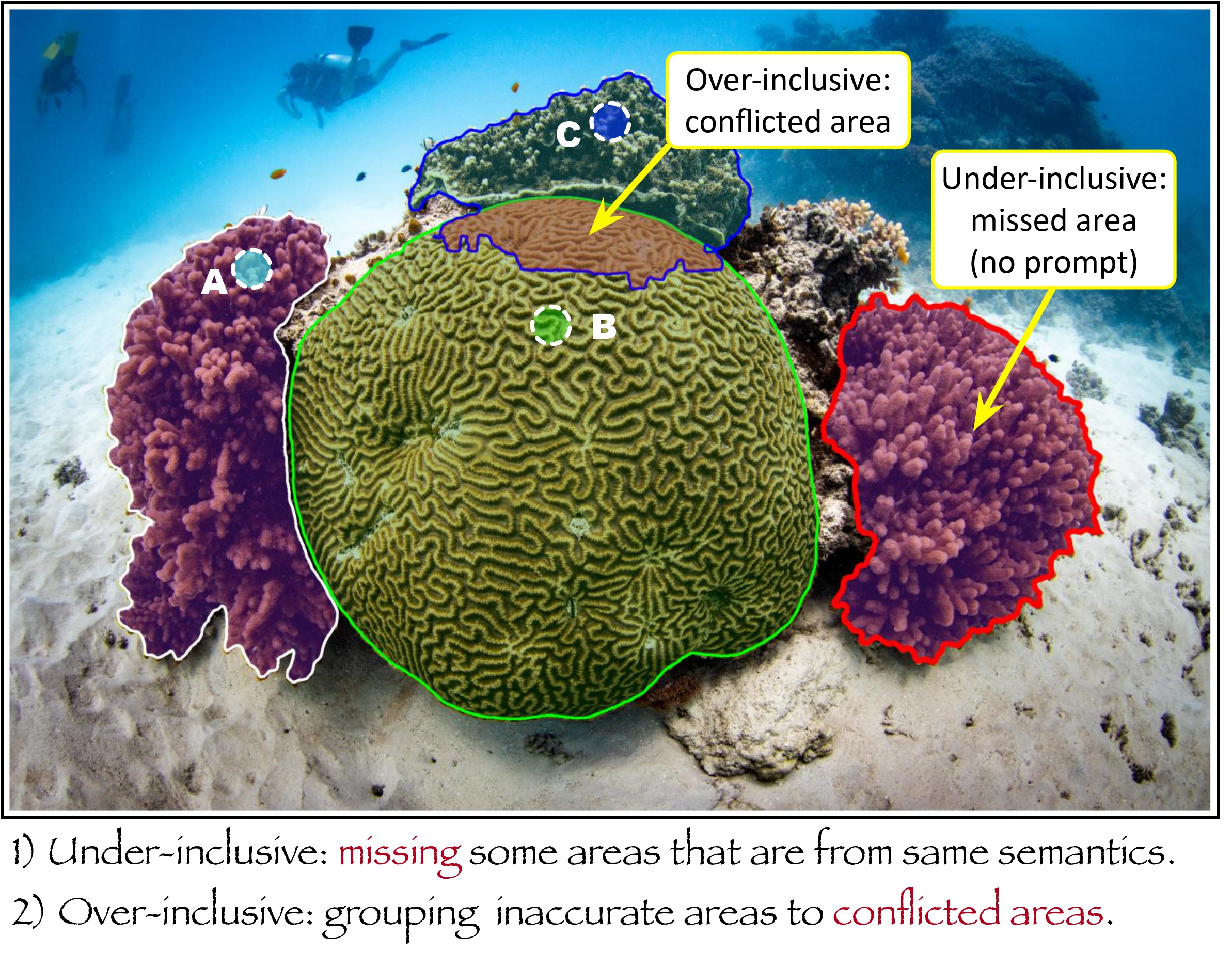
Promptable segmentation models (e.g., SAM and CoralSCOP) lead to under-inclusive and over-inclusive outputs. The mask with red edge is for illustration, not model-generated.

The key difference between segmenting the fish and the
corals: the fish has a
visually consistent structural unit while
the corals do not have. No matter which part of the fish
is occluded, we humans can almost imagine its boundary
and shape. But for corals, we cannot imagine a
consistent output from two occluded inputs with
different regions occluded.
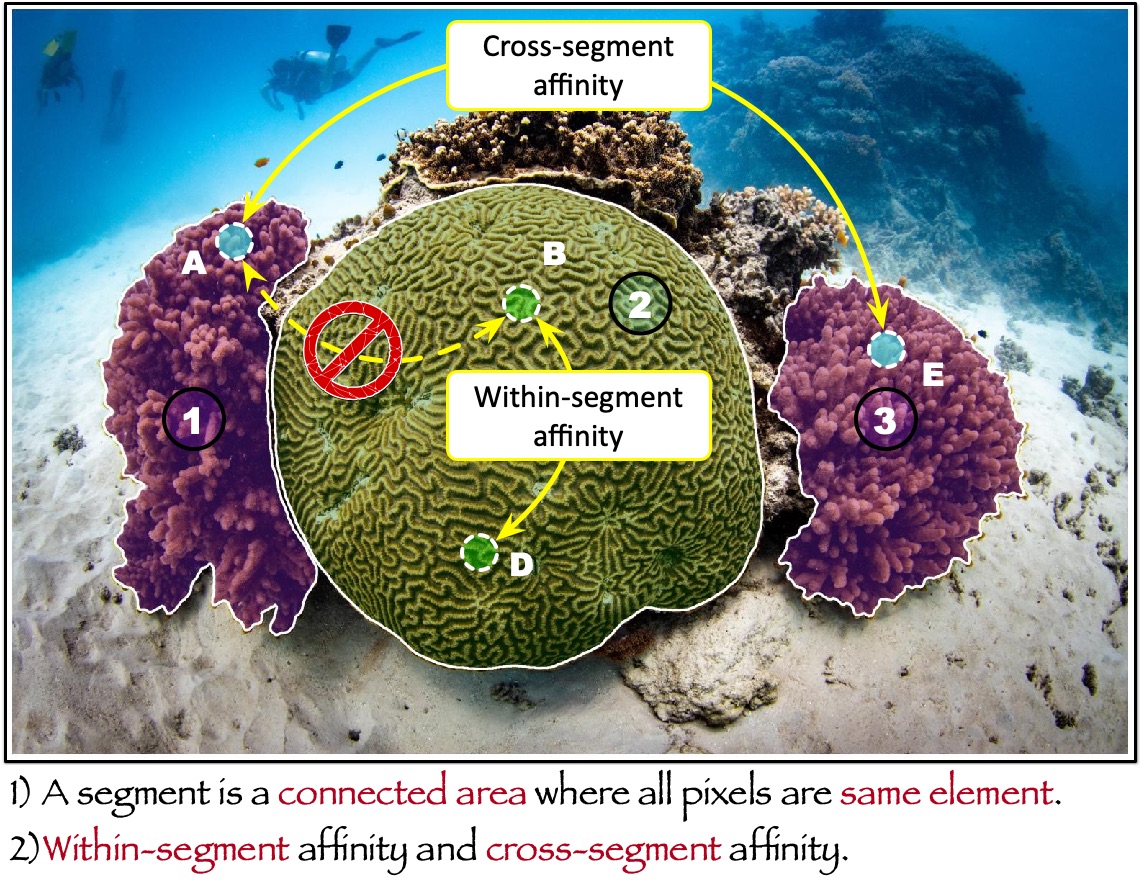
Our simple and fundamental problem formulation for coral reef semantic segmentation: segment as the basis to model within-segment and cross-segment affinities.
PCA visualization

PCA comparison (first 3 channels) of features from different algorithms and foundation models.
Sparse-to-dense conversion

Sparse-to-dense conversion based on features from different algorithms and foundation models.
Zero-shot ability

Zero-shot sparse-to-dense conversion results on the Seaview dataset.
Model-agnostic

Our model could promote the features from various foundation models.